Uma das coisas que eu quero incluir nesse blog são tópicos em econometria. Minha ideia é escrever um post seguindo meus estudos — basicamente fichando (publicamente) o que eu leio. Esse vai ser o primeiro nesse sentido.
Pra começar, vou escrever sobre métodos de Monte Carlo baseados em cadeias de Markov. É um jeito de conduzir inferência Bayesiana quando os modelos que nós queremos estudar são muito difíceis de resolver com papel e caneta. Em macro aplicada, essa estratégia é o ganha-pão em várias áreas — estimação de DSGEs (modelos estocásticos de equilíbrio geral), estimação de VARs (modelos autorregressivos vetoriais), entre outros.
A referência que eu vou seguir hoje é Computational Statistics Handbook with Matlab (escrito por Wendy Martinez e Angel Martinez), capítulo onze. Os códigos serão escritos em Python.
Inferência Bayesiana
Meu professor de macro do primeiro ano do doutorado vivia perguntando pra gente o que é um modelo econômico? A pergunta era uma pegadinha porque o primeiro instinto é responder algo como “uma simplificação matemática da realidade”, mas a resposta correta é “uma distribuição de probabilidade”. A distinção é bem sutil e também não é assunto para hoje.
Enfim, vamos trabalhar com uma distribuição de probabilidade sobre coisas observáveis 



O que para mim sempre foi meio esquisito porque o que significa um parâmetro ser uma variável aleatória? A resposta que me deixou satisfeito é que os parâmetros não são uma variável aleatória (até porque isso não faria muito sentido quando os resultados Bayesianos são iguais aos da estatística clássica), mas que nós os tratamos como aleatórios devido à nossa ignorância/falta de conhecimento.
Nós descrevemos essa ignorância usando uma distribuição de probabilidades, 

Inferência Bayesiana é o processo de aprendizado dos parâmetros conforme observamos os dados. Isso é, a distribuição a posteriori (posterior):

E essa igualdade é a regra de Bayes. Via de regra, o problema é o denominador (a constante de integração) que é difícil de calcular. Ainda bem que os métodos que eu vou descrever aqui não dependem de saber a constante de integração diretamente. Por isso pode se escrever

sem problema algum. (
Metropolis-Hastings
Vamos falar do algoritmo Metropolis-Hastings para amostrar de uma cadeia de Markov. Uma cadeia de Markov é uma sequência de variáveis aleatórias onde cada realização depende apenas da realização anterior. (Ou, caso isso não seja verdade diretamente, onde é possível reescrever o modelo e essa condição se verifique.)
Definição (cadeia de Markov): Uma cadeia de Markov é uma sequência de variáveis aleatórias 


Cadeias de Markov aparecem em todo lugar em macro. Os modelos DSGE clássicos que eu falei no começo são escritos com processos markovianos; VARs também admitem uma representação como um processo de Markov. (Já estou vendo que vai ter post sobre isso num futuro próximo 🙂 Hoje vou deixar bem geral mesmo e depois eu retorno para esse post.) De qualquer jeito, nossos modelos tradicionais são markovianos mas isso não quer dizer que seja fácil de estudá-los — a dificuldade reside justamente em obter amostras desse processo estocástico!
O algoritmo Metropolis-Hastings (MH) é um jeito de contornar esse problema usando uma distribuição auxiliar. Isso foi revolucionário quando foi descoberto nos anos 50 porque já sabíamos como tirar amostras aleatórias de algumas distribuições e agora podemos usá-las para amostrar de outras. Vamos chamar essa distribuição de 
A ideia é “aceitar” um candidato 

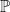

Essa medida de “proximidade” é a probabilidade

Se o ponto 

O algoritmo funciona assim:
- Dê um “chute inicial”,
- Use
para gerar um candidato Y
- Calcule a “proximidade” e gere um número uniforme U entre 0 e 1
- Se U for maior que a “proximidade”, rejeite o candidato (
) e repita o procedimento; caso contrário, aceite (
)
- Repita os três passos anteriores até a sequência “convergir”

Um exemplo completo
Vou encerrar o post de hoje com um exemplo completo em Python. O objetivo é simular números aleatórios de uma distribuição de valores extremos generalizada. Essa distribuição tem três parâmetros, 
Uma coisa complicada é que o suporte da distribuição muda dependendo dos parâmetros. Se 


A densidade é

onde
![t(x) \equiv \begin{cases} [1+\sigma^{-1}\xi(x-\mu)] & \text{ se } \xi \neq 0 \\ exp(-\sigma^{-1}(x-\mu)) & \text{ caso contrário} \end{cases}](https://s0.wp.com/latex.php?latex=t%28x%29+%5Cequiv+%5Cbegin%7Bcases%7D+%5B1%2B%5Csigma%5E%7B-1%7D%5Cxi%28x-%5Cmu%29%5D+%26+%5Ctext%7B+se+%7D+%5Cxi+%5Cneq+0+%5C%5C+exp%28-%5Csigma%5E%7B-1%7D%28x-%5Cmu%29%29+%26+%5Ctext%7B+caso+contr%C3%A1rio%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=000&s=0&c=20201002)
No Python, a primeira coisa é escrever essa pdf.
def gev(x, mu, sigma, xi):
# verificar o suporte...
if ((xi > 0) & (x < mu - sigma/xi)) | ((xi < 0) & (x > mu - sigma/xi)):
return 0 # já sai se der errado
# calcular t
if xi == 0:
t = np.exp((mu-x)/sigma)
else:
t = (1 + xi * (x-mu)/sigma) ** (-1/xi)
# calcular f
f = t ** (xi + 1) * np.exp(-t)
return fPra minha distribuição candidata eu vou escolher uma gaussiana (mas poderia ser outra, claro!).

A pdf é
def npdf(x, mu, sigma):
# sigma é o desvio padrão
z = (x-mu)/sigma
c = 1/np.sqrt(2 * np.pi)/sigma
return c * np.exp(-1/2 * z**2) Vamos começar a gerar os números de uma GEV(0, 1, 0.5). Como 

# Declarações
N = 10000 # tamanho da amostra
X = np.zeros((N,))
# parâmetros da GEV
mu_GEV = 0
sigma_GEV = 1
xi_GEV = 0.5
# parâmetros da normal (candidata)
sigma_normal = np.sqrt(0.5)
# chute inicial
X[0] = 1
for i in range(1,N):
# Gerar número da candidata
y = np.random.normal(X[i-1], sigma_normal)
# quantidades da proximidade...
p_y = gev(y, mu_GEV, sigma_GEV, xi_GEV)
p_X = gev(X[i-1], mu_GEV, sigma_GEV, xi_GEV)
q_y_X = npdf(y, X[i-1], sigma_normal)
q_X_y = npdf(X[i-1], y, sigma_normal)
# calculando efetivamente
alfa = np.minimum(1, p_y/p_X * q_X_y/q_y_X)
# gerar uniforme
u = np.random.uniform()
# aceita/rejeita
if u < alfa:
X[i] = y
else:
X[i] = X[i-1]Agora, vamos ver o resultado. O histograma das simulações é:
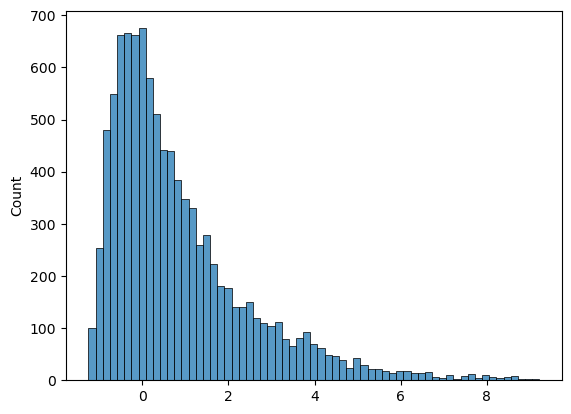
E a cadeia evolui desse jeito no começo (primeiras 200 simulações):

Analisar a evolução da cadeia vai ser assunto de um post no futuro também.
Esse post é o primeiro de uma série de posts sobre esse tipo de estimação. Meu objetivo é ir em detalhes nesses algoritmos e no fim fazer uma aplicação de verdade pra escrever um post. No próximo artigo dessa série, vou passar por mais alguns algoritmos. Até a próxima!

Deixe um comentário