Hoje eu vi esse tuíte mostrando a taxa de desemprego e a média das projeções do relatório Focus:

Uma boa parte, se não a maioria, das respostas tem o mesmo tema (o “mercado” torce para a taxa de desemprego subir).
A pergunta que fica é como que os entrevistados erram sistematicamente na mesma direção. Minha resposta é que isso não é torcida mas simplesmente porque talvez não dê para fazer dinheiro prevendo bem a taxa de desemprego.
Se não tem grana envolvida, acaba que ninguém se importa em prever desemprego. E`ntão, pra enviar as respostas da pesquisa, o mais fácil é rodar um modelo estatístico simples qualquer. O modelo básico para séries temporais é um modelo autoregressivo (AR), que, no fim do dia, nada mais é do que uma correlação. A equação de um AR com um só período é a seguinte:






Nós podemos usar esse modelo para prever o desemprego. De largada, modelos AR têm uma característica importante: eles querem voltar para o valor médio da série no futuro. Previsões desse modelo, então, vão ficando cada vez mais perto da média da série à medida que o horizonte de previsão aumenta.
O que eu fiz, então, é rodar um modelo AR (com mais valores antigos para previsão, seis no total) para construir o mesmo gráfico do tuíte original.
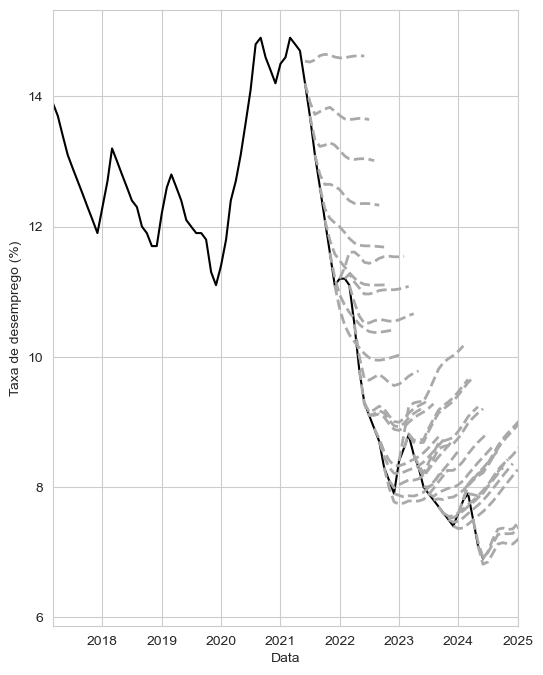
Como a média é alta (10.5% entre 2012 e 2022), as previsões vão sendo puxadas para cima. Tá explicado.
Código para replicação
# Importar pacotes
import ipeadatapy as ipd
import numpy as np
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
# Baixar dados do ipeadata
desemprego = ipd.timeseries('PNADC12_TDESOC12')
desemprego = desemprego.loc[:, 'VALUE ((%))']
desemprego.index.name = 'Data'
desemprego.rename('Taxa de desemprego (%)', inplace=True)
desemprego = desemprego.loc[desemprego.index.year >= 2012]
# Calcular tentáculos
tentaculos = pd.DataFrame(index = pd.date_range('05-01-2021', '06-01-2024', freq='MS'),
columns = pd.date_range('06-01-2021', '06-01-2025', freq='MS'))
for t in pd.date_range('05-01-2021', '06-01-2024', freq='MS'):
# train autoregression
model = AutoReg(desemprego.loc[:t], lags=6)
model_fit = model.fit()
predictions = model_fit.predict(start=len(desemprego.loc[:t]), end=len(desemprego.loc[:t])+12, dynamic=False)
tentaculos.loc[t, pd.date_range(t+pd.DateOffset(months=1), t+pd.DateOffset(months=13), freq='MS')] = predictions
# Plotar
fig, ax = plt.subplots(figsize=(6, 8))
sns.lineplot(desemprego, ax=ax, color='black')
dff = tentaculos.T
for j in dff.index:
try:
dff.loc[j,j] = desemprego.loc[j]
except:
pass
for j in dff.columns:
sns.lineplot(dff.loc[:,j], color='darkgrey', linestyle='--', linewidth=2, ax=ax)
ax.set(xlim=(pd.to_datetime('3/1/2017'), pd.to_datetime('1/1/2025')))
Deixe um comentário