Hoje vamos ver mais alguns algoritmos. O Metropolis-Hastings que eu discuti no primeiro post é muito geral. Apesar de isso geralmente ser uma coisa boa, sempre vai existir uma escolha entre generalidade e tempo computacional. No caso, um lugar onde nós poderíamos ter economizado tempo é no cálculo da pdf da normal, que foi a distribuição auxiliar. Claro, na escala do exemplo de ontem isso não faz nenhuma diferença na prática. Porém, pode ser difícil calcular 

(que é o caso da normal). A nova probabilidade então fica

Esse é o algoritmo Metropolis — nada muito interessante. Vamos para algo mais interessante agora.
O amostrador de Gibbs
O amostrador de Gibbs (Gibbs sampler) é o que ajuda muito a fazer estimações Bayesianas. Mesmo sendo um caso particular do Metropolis-Hastings, vale a pena estudar ele separado porque ele tem umas propriedades interessantes, e uma dificuldade séria.
Primeiro, a vantagem. O amostrador de Gibbs é um Metropolis-Hastings onde se aceitam todos os candidatos (então cada ponto será um ponto da posterior). Isso ajuda muito computacionalmente porque agora não temos que nos preocupar com a taxa de rejeição.
O custo é que nós devemos saber (e amostrar rapidamente) de distribuições condicionais. Por exemplo, digamos que queremos amostrar de uma distribuição bi-variada 

O que parece fácil mas fica difícil muito rápido para problemas que distoam um pouco do padrão. (Uma vez eu precisei usar um Gibbs para uma normal truncada e não foi exatamente simples.)
A ideia do amostrador de Gibbs é usar essas distribuições condicionais e amostrar parte por parte. Como antes, vamos iniciar uma cadeia de um ponto 
Agora, condicional a 


Agora vamos amostrar 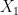
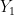

Após esse passo nós obtemos a primeira amostra 


E assim por diante. O algoritmo então fica:
- Inicie a cadeia em
- Condicional a
, gere
- Condicional a
- Itere nos dois últimos passos
Um exemplo completo
Vamos amostrar de uma normal bivariada com o amostrador de Gibbs,

Onde 


Nesse caso, é importante lembrar que a distribuição de 



Vamos primeiro fazer uma função pra dar esses parâmetros das distribuições condicionais.
def param_cond(mu, Sigma, y1, y2):
mu1 = mu[0] + Sigma[0,1]/Sigma[1,1] * (y2 - mu[1])
mu2 = mu[1] + Sigma[0,1]/Sigma[0,0] * (y1 - mu[0])
s1 = Sigma[0,0] - Sigma[0,1]**2 / Sigma[1,1]
s2 = Sigma[1,1] - Sigma[0,1]**2 / Sigma[0,0]
return mu1, mu2, s1, s2Vamos então iniciar a cadeia. Como já sabemos a média, vou começar por ali. Então, vou amostrar 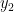
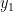
B = 10000 # número de repetições
# Parâmetros
mu = np.array([1,2])
Sigma = np.array([[2, 1], [1,3]])
# Declarando o vetor
Y = np.zeros((2,B))
Y[:,0] = mu #chute inicial
for j in range(1,B):
# Primeiro passo -> amostrar y_2 | y_1
m1, m2, s1, s2 = param_cond(mu, Sigma, Y[0,j-1], Y[1,j-1]) # O segundo y nao importa e só vamos usar m2 e s2 agora
s2 = np.sqrt(s2) # Transformar variância em desvio padrão
Y[1,j] = np.random.normal(m2, s2)
# Segundo passo -> amostrar y_1 | y_2
m1, m2, s1, s2 = param_cond(mu, Sigma, Y[0,j-1], Y[1,j]) # O primeiro y nao importa e só vamos usar m1 e s1 agora
s1 = np.sqrt(s1) # Transformar variância em desvio padrão
Y[0,j] = np.random.normal(m1, s1)Daí é só plotar:

Código para plotar
df = pd.DataFrame(Y.T, columns=['y_1','y_2'])
sns.kdeplot(data=df, x='y_1', y='y_2')
plt.axhline(y=mu[1], c='red', linestyle='dashed')
plt.axvline(x=mu[0], c='red', linestyle='dashed')Pronto! No próximo post da série vou estimar uma regressão linear. Até lá!

Deixe um comentário