Que fazer previsões não é nenhum passeio todo mundo sabe, ainda mais em uma economia volátil como a brasileira. Porém, atribuir erros de previsão à uma briga do mercado contra o governo beira ser uma teoria da conspiração — no sentido literal da coisa.
Para que haja de fato uma torcida contra o governo, com sugeriram vários artigos às vésperas do Natal e do Ano Novo, as previsões têm de ter um erro sistemático do mercado como um todo, e não apenas erros da previsão média (ou mediana). Apesar de, sim, os dados de expectativas médias poderem ser lidos como sinais de otimismo ou pessimismo sobre a situação do país, uma análise justa sobre as previsões tem de também levar em consideração ao menos a discordância1 entre os entrevistados.
Os dados trimestrais do PIB mostram que, na verdade, é incomum o mercado como um todo errar sistematicamente. Ao considerar a banda total de opiniões, verificam-se poucos períodos de erros consistentes (nos arredores da crise financeira de 2008 e no período pós-pandemia, começando em 2021). Não aparenta haver nenhum tipo de viés contra qualquer presidente em específico desde 2016. Olhando para a inflação mensalmente, há menos evidência ainda. Caso o mercado de fato jogasse contra o governo para influenciar políticas econômicas (principalmente a monetária), nós veríamos padrões de erros persistentes na direção que mais conviesse.
Os dados anuais, seguindo a lógica de pegar as expectativas no primeiro dia útil, mostram uma figura similar: não existem alguns períodos viés sistemático contra algum governo, uma vez que a conjuntura tenha sido levada em conta.
Primeiro, vemos um leve viés negativo contra os governos na segunda metade do governo Lula 1, porém isso é marcado pela saída do então Ministro Antônio Palocci Filho (que foi chave em manter a economia nos eixos durante a transição FHC-Lula). Os erros de previsão durante Lula 2 são certamente marcados pela crise mundial do subprime.
Segundo, há vieses positivos durante os governos Dilma 1 e 2, indo diretamente contra a ideia de uma torcida contra governos mais à esquerda. Vale ressaltar que a doutrina da Nova Matriz Econômica operava a todo vapor durante o primeiro governo Dilma. O esgotamento do modelo ainda manteve o mercado esperançoso com a Fazenda sendo liderada por Joaquim Levy, que à época deu um alívio ao mercado mesmo sabendo-se que nem tudo o que foi prometido seria levado a cabo.
Terceiro, apesar do otimismo inicial no governo Bolsonaro, o pessimismo também rondou já em 2022. Considerando que as expectativas mostradas acima são do início do ano, que era ano eleitoral, e que candidatura de Lula deu-se somente em julho, até poderia-se argumentar que mercado jogou contra o governo ali — claro, apenas no caso que o então presidente fosse outra pessoa, mantendo o resto constante.
É difícil sustentar o ponto de que o mercado age contra governo tendo isso em vista. Considerando ainda que o Partido dos Trabalhadores governou por 17 dos últimos 23 anos, a tese de que o mercado tenha qualquer picuinha contra o governo de maneira sistêmica cai água abaixo.
O Federal Reserve de Nova Iorque publicou um artigo interessante sobre discordância e sobre incerteza [Link] ↩︎
A referência básica para esse post é Zellner (1970)
Nesse post nós vamos estimar uma regressão linear com duas variáveis, um regressando e um regressor.
O regressando e o regressor são números reais, são termos aleatórios. Os parâmetros de interesse são e , que eu vou colocar em um vetor . O modelo (a verossimilhança) é . No fim, temos um vetor de parâmetros, .
Mecanicamente, o processo funciona assim: nós começamos com uma distribuição a priori sobre os parâmetros, observamos os dados, e atualizamos essa distribuição (a posteriori). O objetivo é encontrar a “distribuição dos parâmetros”. Aqui eu acho que vale um adendo. Eu já vi muita gente falando que os parâmetros são uma variável aleatória. No meu ponto de vista, eles não são variáveis aleatórias mas sim são tratados como aleatórios porque a aleatoriedade apenas reflete nossa falta de conhecimento sobre eles.
Ou seja, nós iniciamos com uma descrição do nosso conhecimento acerca os parâmetros do modelo (ou a falta dele). Daí observamos os dados e atualizamos essa descrição. Seguindo o primeiro post dessa saga,
No fim do dia, vamos obter amostras aleatórias de , e por isso passamos os últimos dois posts fazendo esse tipo de coisa. Vamos gerar uma amostra de usando
com e
Vou iniciar o código incluindo alguns pacotes e definindo a pdf da normal.
import numpy as np
import pandas as pd
import seaborn as sns
from scipy.stats import norm as gauss, uniform
def ll_normal(theta, x, y):
n = x.shape[0]
e = y - theta[0] - theta[1] * x
variancia = theta[2]
if variancia <= 0: # variância não pode ser negativa
return -np.inf
else:
ll = -0.5 * n * np.log(2 * np.pi * variancia) - np.sum(e**2) / (2 * variancia)
return ll
Uma amostra típica…
Para gerar essa amostra, eu uso o seguinte código:
# Parâmetros
N = 500
b0 = 2
b1 = 0.5
sigma2e = 1
sigma2x = 1.5
y = np.zeros((N,))
x = np.zeros((N,))
# Gerar amostra
x = gauss.rvs(size=N) * np.sqrt(sigma2x)
e = gauss.rvs(size=N) * np.sqrt(sigma2e)
y = b0 + b1 * x + e
df = pd.DataFrame({'y': y, 'x': x})
sns.scatterplot(df, x='x', y='y')
Para amostrar da distribuição a posteriori, vamos aplicar o algoritmo Metropolis-Hastings.
1. Iniciar a cadeia. Aqui, a cadeia começa no ponto (0,0,1).
B = 10000
theta = np.zeros((B,3))
theta[0,2] = 1
2. Gerar um candidato. Vou gerar usando uma distribuição normal (então o Metropolis-Hastings vai ser igual ao Metropolis).
Hoje vamos ver mais alguns algoritmos. O Metropolis-Hastings que eu discuti no primeiro post é muito geral. Apesar de isso geralmente ser uma coisa boa, sempre vai existir uma escolha entre generalidade e tempo computacional. No caso, um lugar onde nós poderíamos ter economizado tempo é no cálculo da pdf da normal, que foi a distribuição auxiliar. Claro, na escala do exemplo de ontem isso não faz nenhuma diferença na prática. Porém, pode ser difícil calcular . Então seria bom evitar. Na realidade, isso não é complicado: basta escolher uma distribuição que satisfaça
(que é o caso da normal). A nova probabilidade então fica
Esse é o algoritmo Metropolis — nada muito interessante. Vamos para algo mais interessante agora.
O amostrador de Gibbs
O amostrador de Gibbs (Gibbs sampler) é o que ajuda muito a fazer estimações Bayesianas. Mesmo sendo um caso particular do Metropolis-Hastings, vale a pena estudar ele separado porque ele tem umas propriedades interessantes, e uma dificuldade séria.
Primeiro, a vantagem. O amostrador de Gibbs é um Metropolis-Hastings onde se aceitam todos os candidatos (então cada ponto será um ponto da posterior). Isso ajuda muito computacionalmente porque agora não temos que nos preocupar com a taxa de rejeição.
O custo é que nós devemos saber (e amostrar rapidamente) de distribuições condicionais. Por exemplo, digamos que queremos amostrar de uma distribuição bi-variada . Para aplicar o método de Gibbs, temos de saber amostrar de
O que parece fácil mas fica difícil muito rápido para problemas que distoam um pouco do padrão. (Uma vez eu precisei usar um Gibbs para uma normal truncada e não foi exatamente simples.)
A ideia do amostrador de Gibbs é usar essas distribuições condicionais e amostrar parte por parte. Como antes, vamos iniciar uma cadeia de um ponto .
Agora, condicional a , vamos amostrar um novo valor para ,
Agora vamos amostrar , condicional a ,
Após esse passo nós obtemos a primeira amostra . Para obter as próximas, repetimos os passos,
E assim por diante. O algoritmo então fica:
Inicie a cadeia em
Condicional a , gere
Condicional a , gere
Itere nos dois últimos passos
Um exemplo completo
Vamos amostrar de uma normal bivariada com o amostrador de Gibbs,
Onde é a média e é uma matrix de covariâncias. Vamos botar alguns números:
Nesse caso, é importante lembrar que a distribuição de é normal com média e variância . Dá pra achar a média e variância de do mesmo jeito.
Vamos primeiro fazer uma função pra dar esses parâmetros das distribuições condicionais.
Vamos então iniciar a cadeia. Como já sabemos a média, vou começar por ali. Então, vou amostrar condicional a , e assim por diante. Mais fácil ver no código mesmo…
B = 10000 # número de repetições
# Parâmetros
mu = np.array([1,2])
Sigma = np.array([[2, 1], [1,3]])
# Declarando o vetor
Y = np.zeros((2,B))
Y[:,0] = mu #chute inicial
for j in range(1,B):
# Primeiro passo -> amostrar y_2 | y_1
m1, m2, s1, s2 = param_cond(mu, Sigma, Y[0,j-1], Y[1,j-1]) # O segundo y nao importa e só vamos usar m2 e s2 agora
s2 = np.sqrt(s2) # Transformar variância em desvio padrão
Y[1,j] = np.random.normal(m2, s2)
# Segundo passo -> amostrar y_1 | y_2
m1, m2, s1, s2 = param_cond(mu, Sigma, Y[0,j-1], Y[1,j]) # O primeiro y nao importa e só vamos usar m1 e s1 agora
s1 = np.sqrt(s1) # Transformar variância em desvio padrão
Y[0,j] = np.random.normal(m1, s1)
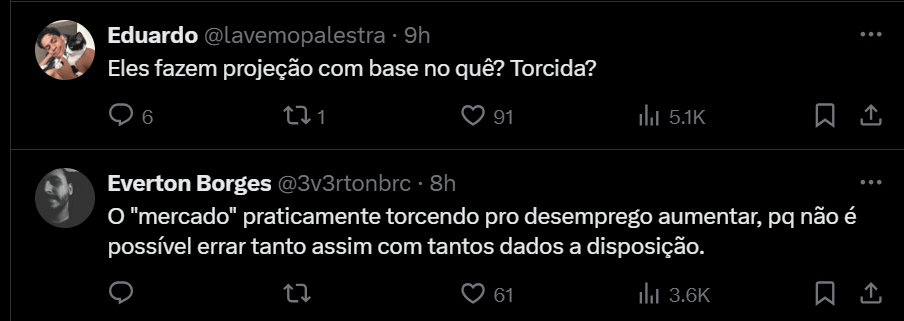
Hoje eu vi esse tuíte mostrando a taxa de desemprego e a média das projeções do relatório Focus:
Uma boa parte, se não a maioria, das respostas tem o mesmo tema (o “mercado” torce para a taxa de desemprego subir).
A pergunta que fica é como que os entrevistados erram sistematicamente na mesma direção. Minha resposta é que isso não é torcida mas simplesmente porque talvez não dê para fazer dinheiro prevendo bem a taxa de desemprego.
Se não tem grana envolvida, acaba que ninguém se importa em prever desemprego. E`ntão, pra enviar as respostas da pesquisa, o mais fácil é rodar um modelo estatístico simples qualquer. O modelo básico para séries temporais é um modelo autoregressivo (AR), que, no fim do dia, nada mais é do que uma correlação. A equação de um AR com um só período é a seguinte:
é a taxa de desemprego numa data qualquer (), é um termo de erro (porque o modelo não prevê corretamente), e e são parâmetros.
Nós podemos usar esse modelo para prever o desemprego. De largada, modelos AR têm uma característica importante: eles querem voltar para o valor médio da série no futuro. Previsões desse modelo, então, vão ficando cada vez mais perto da média da série à medida que o horizonte de previsão aumenta.
O que eu fiz, então, é rodar um modelo AR (com mais valores antigos para previsão, seis no total) para construir o mesmo gráfico do tuíte original.
Como a média é alta (10.5% entre 2012 e 2022), as previsões vão sendo puxadas para cima. Tá explicado.
Código para replicação
# Importar pacotes
import ipeadatapy as ipd
import numpy as np
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
# Baixar dados do ipeadata
desemprego = ipd.timeseries('PNADC12_TDESOC12')
desemprego = desemprego.loc[:, 'VALUE ((%))']
desemprego.index.name = 'Data'
desemprego.rename('Taxa de desemprego (%)', inplace=True)
desemprego = desemprego.loc[desemprego.index.year >= 2012]
# Calcular tentáculos
tentaculos = pd.DataFrame(index = pd.date_range('05-01-2021', '06-01-2024', freq='MS'),
columns = pd.date_range('06-01-2021', '06-01-2025', freq='MS'))
for t in pd.date_range('05-01-2021', '06-01-2024', freq='MS'):
# train autoregression
model = AutoReg(desemprego.loc[:t], lags=6)
model_fit = model.fit()
predictions = model_fit.predict(start=len(desemprego.loc[:t]), end=len(desemprego.loc[:t])+12, dynamic=False)
tentaculos.loc[t, pd.date_range(t+pd.DateOffset(months=1), t+pd.DateOffset(months=13), freq='MS')] = predictions
# Plotar
fig, ax = plt.subplots(figsize=(6, 8))
sns.lineplot(desemprego, ax=ax, color='black')
dff = tentaculos.T
for j in dff.index:
try:
dff.loc[j,j] = desemprego.loc[j]
except:
pass
for j in dff.columns:
sns.lineplot(dff.loc[:,j], color='darkgrey', linestyle='--', linewidth=2, ax=ax)
ax.set(xlim=(pd.to_datetime('3/1/2017'), pd.to_datetime('1/1/2025')))
Uma das coisas que eu quero incluir nesse blog são tópicos em econometria. Minha ideia é escrever um post seguindo meus estudos — basicamente fichando (publicamente) o que eu leio. Esse vai ser o primeiro nesse sentido.
Pra começar, vou escrever sobre métodos de Monte Carlo baseados em cadeias de Markov. É um jeito de conduzir inferência Bayesiana quando os modelos que nós queremos estudar são muito difíceis de resolver com papel e caneta. Em macro aplicada, essa estratégia é o ganha-pão em várias áreas — estimação de DSGEs (modelos estocásticos de equilíbrio geral), estimação de VARs (modelos autorregressivos vetoriais), entre outros.
A referência que eu vou seguir hoje é Computational Statistics Handbook with Matlab (escrito por Wendy Martinez e Angel Martinez), capítulo onze. Os códigos serão escritos em Python.
Inferência Bayesiana
Meu professor de macro do primeiro ano do doutorado vivia perguntando pra gente o que é um modelo econômico? A pergunta era uma pegadinha porque o primeiro instinto é responder algo como “uma simplificação matemática da realidade”, mas a resposta correta é “uma distribuição de probabilidade”. A distinção é bem sutil e também não é assunto para hoje.
Enfim, vamos trabalhar com uma distribuição de probabilidade sobre coisas observáveis e um conjunto de parâmetros , . Usando regras de probabilidade,
O que para mim sempre foi meio esquisito porque o que significa um parâmetro ser uma variável aleatória? A resposta que me deixou satisfeito é que os parâmetros não são uma variável aleatória (até porque isso não faria muito sentido quando os resultados Bayesianos são iguais aos da estatística clássica), mas que nós os tratamos como aleatórios devido à nossa ignorância/falta de conhecimento.
Nós descrevemos essa ignorância usando uma distribuição de probabilidades, , que vamos chamar de prior (a priori, pressuposta). A outra parte é a verossimilhança, , que descreve os observáveis dependendo dos parâmetros.
Inferência Bayesiana é o processo de aprendizado dos parâmetros conforme observamos os dados. Isso é, a distribuição a posteriori (posterior):
E essa igualdade é a regra de Bayes. Via de regra, o problema é o denominador (a constante de integração) que é difícil de calcular. Ainda bem que os métodos que eu vou descrever aqui não dependem de saber a constante de integração diretamente. Por isso pode se escrever
sem problema algum. ( significando “proporcional”, ou seja, faltando só multiplicar por uma constante.)
Metropolis-Hastings
Vamos falar do algoritmo Metropolis-Hastings para amostrar de uma cadeia de Markov. Uma cadeia de Markov é uma sequência de variáveis aleatórias onde cada realização depende apenas da realização anterior. (Ou, caso isso não seja verdade diretamente, onde é possível reescrever o modelo e essa condição se verifique.)
Definição (cadeia de Markov): Uma cadeia de Markov é uma sequência de variáveis aleatórias que satisfaz e é o “kernel” de transição.
Cadeias de Markov aparecem em todo lugar em macro. Os modelos DSGE clássicos que eu falei no começo são escritos com processos markovianos; VARs também admitem uma representação como um processo de Markov. (Já estou vendo que vai ter post sobre isso num futuro próximo 🙂 Hoje vou deixar bem geral mesmo e depois eu retorno para esse post.) De qualquer jeito, nossos modelos tradicionais são markovianos mas isso não quer dizer que seja fácil de estudá-los — a dificuldade reside justamente em obter amostras desse processo estocástico!
O algoritmo Metropolis-Hastings (MH) é um jeito de contornar esse problema usando uma distribuição auxiliar. Isso foi revolucionário quando foi descoberto nos anos 50 porque já sabíamos como tirar amostras aleatórias de algumas distribuições e agora podemos usá-las para amostrar de outras. Vamos chamar essa distribuição de .
A ideia é “aceitar” um candidato da distribuição se ele for “próximo” de algo que veríamos da distribuição de interesse original . De novo, vamos fazer isso porque é difícil amostrar de (que tem densidade ), mas é fácil tirar uma amostra de .
Essa medida de “proximidade” é a probabilidade
Se o ponto da distribuição candidata não for aceito, então a cadeia não move (); caso contrário, .
O algoritmo funciona assim:
Dê um “chute inicial”,
Use para gerar um candidato Y
Calcule a “proximidade” e gere um número uniforme U entre 0 e 1
Se U for maior que a “proximidade”, rejeite o candidato () e repita o procedimento; caso contrário, aceite ()
Repita os três passos anteriores até a sequência “convergir”
Um exemplo completo
Vou encerrar o post de hoje com um exemplo completo em Python. O objetivo é simular números aleatórios de uma distribuição de valores extremos generalizada. Essa distribuição tem três parâmetros, que definem localização, escala, e forma, respectivamente.
Uma coisa complicada é que o suporte da distribuição muda dependendo dos parâmetros. Se . Se . Se .
A densidade é
onde
No Python, a primeira coisa é escrever essa pdf.
def gev(x, mu, sigma, xi):
# verificar o suporte...
if ((xi > 0) & (x < mu - sigma/xi)) | ((xi < 0) & (x > mu - sigma/xi)):
return 0 # já sai se der errado
# calcular t
if xi == 0:
t = np.exp((mu-x)/sigma)
else:
t = (1 + xi * (x-mu)/sigma) ** (-1/xi)
# calcular f
f = t ** (xi + 1) * np.exp(-t)
return f
Pra minha distribuição candidata eu vou escolher uma gaussiana (mas poderia ser outra, claro!).
A pdf é
def npdf(x, mu, sigma):
# sigma é o desvio padrão
z = (x-mu)/sigma
c = 1/np.sqrt(2 * np.pi)/sigma
return c * np.exp(-1/2 * z**2)
Vamos começar a gerar os números de uma GEV(0, 1, 0.5). Como , o suporte é truncado em 0, vou escolher . Para terminar, o algoritmo implementado fica assim:
# Declarações
N = 10000 # tamanho da amostra
X = np.zeros((N,))
# parâmetros da GEV
mu_GEV = 0
sigma_GEV = 1
xi_GEV = 0.5
# parâmetros da normal (candidata)
sigma_normal = np.sqrt(0.5)
# chute inicial
X[0] = 1
for i in range(1,N):
# Gerar número da candidata
y = np.random.normal(X[i-1], sigma_normal)
# quantidades da proximidade...
p_y = gev(y, mu_GEV, sigma_GEV, xi_GEV)
p_X = gev(X[i-1], mu_GEV, sigma_GEV, xi_GEV)
q_y_X = npdf(y, X[i-1], sigma_normal)
q_X_y = npdf(X[i-1], y, sigma_normal)
# calculando efetivamente
alfa = np.minimum(1, p_y/p_X * q_X_y/q_y_X)
# gerar uniforme
u = np.random.uniform()
# aceita/rejeita
if u < alfa:
X[i] = y
else:
X[i] = X[i-1]
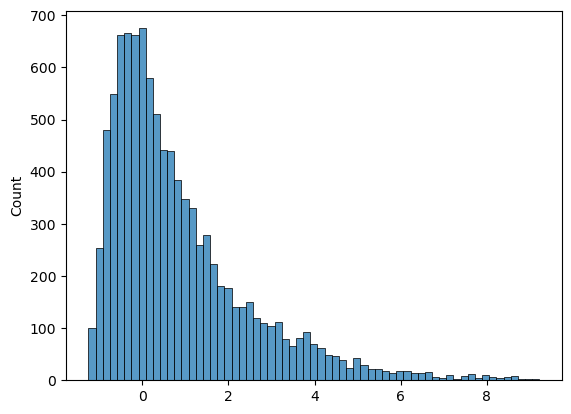
Agora, vamos ver o resultado. O histograma das simulações é:
E a cadeia evolui desse jeito no começo (primeiras 200 simulações):
Analisar a evolução da cadeia vai ser assunto de um post no futuro também.
Esse post é o primeiro de uma série de posts sobre esse tipo de estimação. Meu objetivo é ir em detalhes nesses algoritmos e no fim fazer uma aplicação de verdade pra escrever um post. No próximo artigo dessa série, vou passar por mais alguns algoritmos. Até a próxima!



 e o regressor
e o regressor  são números reais,
são números reais, 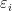 são termos aleatórios. Os parâmetros de interesse são
são termos aleatórios. Os parâmetros de interesse são 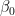 e
e  , que eu vou colocar em um vetor
, que eu vou colocar em um vetor  . O modelo (a verossimilhança) é
. O modelo (a verossimilhança) é  . No fim, temos um vetor de parâmetros,
. No fim, temos um vetor de parâmetros,  .
.
 , e por isso passamos os últimos dois posts fazendo esse tipo de coisa. Vamos gerar uma amostra de
, e por isso passamos os últimos dois posts fazendo esse tipo de coisa. Vamos gerar uma amostra de  usando
usando com
com  e
e 


 . Então seria bom evitar. Na realidade, isso não é complicado: basta escolher uma distribuição que satisfaça
. Então seria bom evitar. Na realidade, isso não é complicado: basta escolher uma distribuição que satisfaça

 . Para aplicar o método de Gibbs, temos de saber amostrar de
. Para aplicar o método de Gibbs, temos de saber amostrar de
 .
. , vamos amostrar um novo valor para
, vamos amostrar um novo valor para  ,
,
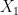 , condicional a
, condicional a 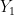 ,
,
 . Para obter as próximas, repetimos os passos,
. Para obter as próximas, repetimos os passos,

 , gere
, gere 
 é a média e
é a média e  é uma matrix de covariâncias. Vamos botar alguns números:
é uma matrix de covariâncias. Vamos botar alguns números:
 é normal com média
é normal com média  e variância
e variância  . Dá pra achar a média e variância de
. Dá pra achar a média e variância de  do mesmo jeito.
do mesmo jeito.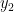 condicional a
condicional a 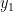 , e assim por diante. Mais fácil ver no código mesmo…
, e assim por diante. Mais fácil ver no código mesmo…


 é a taxa de desemprego numa data qualquer (
é a taxa de desemprego numa data qualquer ( ),
),  é um termo de erro (porque o modelo não prevê corretamente), e
é um termo de erro (porque o modelo não prevê corretamente), e  e
e  são parâmetros.
são parâmetros.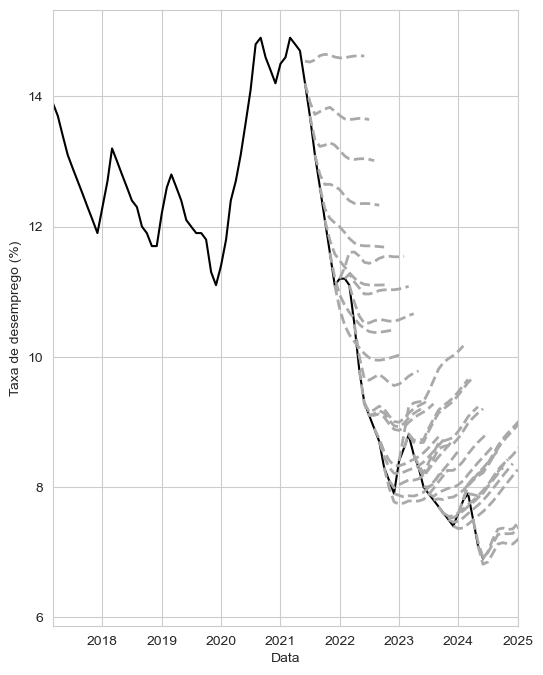
 e um conjunto de parâmetros
e um conjunto de parâmetros  ,
,  . Usando regras de probabilidade,
. Usando regras de probabilidade,
 , que vamos chamar de prior (a priori, pressuposta). A outra parte é a verossimilhança,
, que vamos chamar de prior (a priori, pressuposta). A outra parte é a verossimilhança,  , que descreve os observáveis dependendo dos parâmetros.
, que descreve os observáveis dependendo dos parâmetros. 

 significando “proporcional”, ou seja, faltando só multiplicar por uma constante.)
significando “proporcional”, ou seja, faltando só multiplicar por uma constante.) que satisfaz
que satisfaz  e
e  é o “kernel” de transição.
é o “kernel” de transição. .
. se ele for “próximo” de algo que veríamos da distribuição de interesse original
se ele for “próximo” de algo que veríamos da distribuição de interesse original  . De novo, vamos fazer isso porque é difícil amostrar de
. De novo, vamos fazer isso porque é difícil amostrar de  ), mas é fácil tirar uma amostra de
), mas é fácil tirar uma amostra de 
 ); caso contrário,
); caso contrário,  .
.
 para gerar um candidato Y
para gerar um candidato Y ) e repita o procedimento; caso contrário, aceite (
) e repita o procedimento; caso contrário, aceite ( )
) que definem localização, escala, e forma, respectivamente.
que definem localização, escala, e forma, respectivamente. . Se
. Se  . Se
. Se  .
.
![t(x) \equiv \begin{cases} [1+\sigma^{-1}\xi(x-\mu)] & \text{ se } \xi \neq 0 \\ exp(-\sigma^{-1}(x-\mu)) & \text{ caso contrário} \end{cases}](https://s0.wp.com/latex.php?latex=t%28x%29+%5Cequiv+%5Cbegin%7Bcases%7D+%5B1%2B%5Csigma%5E%7B-1%7D%5Cxi%28x-%5Cmu%29%5D+%26+%5Ctext%7B+se+%7D+%5Cxi+%5Cneq+0+%5C%5C+exp%28-%5Csigma%5E%7B-1%7D%28x-%5Cmu%29%29+%26+%5Ctext%7B+caso+contr%C3%A1rio%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=000&s=0&c=20201002)

 , o suporte é truncado em 0, vou escolher
, o suporte é truncado em 0, vou escolher  . Para terminar, o algoritmo implementado fica assim:
. Para terminar, o algoritmo implementado fica assim: