A referência básica para esse post é Zellner (1970)
Nesse post nós vamos estimar uma regressão linear com duas variáveis, um regressando e um regressor.

O regressando 

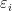
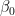




Mecanicamente, o processo funciona assim: nós começamos com uma distribuição a priori sobre os parâmetros, observamos os dados, e atualizamos essa distribuição (a posteriori). O objetivo é encontrar a “distribuição dos parâmetros”. Aqui eu acho que vale um adendo. Eu já vi muita gente falando que os parâmetros são uma variável aleatória. No meu ponto de vista, eles não são variáveis aleatórias mas sim são tratados como aleatórios porque a aleatoriedade apenas reflete nossa falta de conhecimento sobre eles.
Ou seja, nós iniciamos com uma descrição do nosso conhecimento acerca os parâmetros do modelo (ou a falta dele). Daí observamos os dados e atualizamos essa descrição. Seguindo o primeiro post dessa saga,

No fim do dia, vamos obter amostras aleatórias de 




Vou iniciar o código incluindo alguns pacotes e definindo a pdf da normal.
import numpy as np
import pandas as pd
import seaborn as sns
from scipy.stats import norm as gauss, uniform
def ll_normal(theta, x, y):
n = x.shape[0]
e = y - theta[0] - theta[1] * x
variancia = theta[2]
if variancia <= 0: # variância não pode ser negativa
return -np.inf
else:
ll = -0.5 * n * np.log(2 * np.pi * variancia) - np.sum(e**2) / (2 * variancia)
return llUma amostra típica…

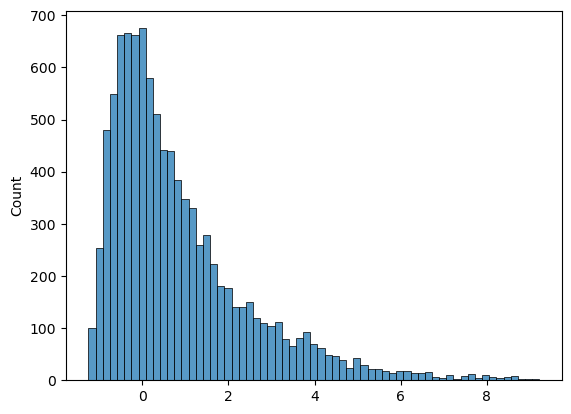
Para gerar essa amostra, eu uso o seguinte código:
# Parâmetros
N = 500
b0 = 2
b1 = 0.5
sigma2e = 1
sigma2x = 1.5
y = np.zeros((N,))
x = np.zeros((N,))
# Gerar amostra
x = gauss.rvs(size=N) * np.sqrt(sigma2x)
e = gauss.rvs(size=N) * np.sqrt(sigma2e)
y = b0 + b1 * x + e
df = pd.DataFrame({'y': y, 'x': x})
sns.scatterplot(df, x='x', y='y')Para amostrar da distribuição a posteriori, vamos aplicar o algoritmo Metropolis-Hastings.
1. Iniciar a cadeia. Aqui, a cadeia começa no ponto (0,0,1).
B = 10000
theta = np.zeros((B,3))
theta[0,2] = 12. Gerar um candidato. Vou gerar usando uma distribuição normal (então o Metropolis-Hastings vai ser igual ao Metropolis).
d_theta = gauss.rvs(size=3) * 1/50
theta_cand = theta[b-1] + d_theta3. Calcular a “distância”.
ll_old = ll_normal(theta[b-1], x, y)
ll_new = ll_normal(theta_cand, x, y)
alpha = np.exp(ll_new - ll_old)4. Aceita/rejeita
u = uniform.rvs(size=1)
if u >= alpha: # rejeita
theta[b,:] = theta[b-1]
else:
theta[b,:] = theta_cand5. Iterar. Na verdade, fica tudo dentro de um loop.
No fim, o código fica assim:
# MCMC - Metropolis-Hastings
B = 10000
theta = np.zeros((B,3))
theta[0,2] = 1
for b in range(1,B):
# Candidato
d_theta = gauss.rvs(size=3) * 1/50
theta_cand = theta[b-1] + d_theta
ll_old = ll_normal(theta[b-1], x, y)
ll_new = ll_normal(theta_cand, x, y)
alpha = np.exp(ll_new - ll_old)
u = uniform.rvs(size=1)
if u >= alpha: # rejeita
theta[b,:] = theta[b-1]
else:
theta[b,:] = theta_candFinalmente, podemos plotar a cadeia. Aqui, vou plotar as últimas 1000 iterações.

Código
df_theta = pd.DataFrame(theta, columns=['b0', 'b1', 's2'])
# Create a figure with 3 subplots, arranged vertically
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(12, 15), sharex=True)
# Plot each time series in its own subplot
df_theta['b0'][-1000:].plot(ax=ax1, ylabel='$\\beta_0$')
df_theta['b1'][-1000:].plot(ax=ax2, ylabel='$\\beta_1$')
df_theta['s2'][-1000:].plot(ax=ax3, ylabel='$\\sigma^2$')
ax1.axhline(b0, color='black', linestyle='-', label='$\\beta_0$')
ax1.axhline(np.mean(df_theta['b0'][-1000:]), color='red', linestyle='--', label='Média')
ax2.axhline(b1, color='black', linestyle='-', label='$\\beta_1$')
ax2.axhline(np.mean(df_theta['b1'][-1000:]), color='red', linestyle='--', label='Média')
ax3.axhline(sigma2e, color='black', linestyle='-', label='$\\sigma^2$')
ax3.axhline(np.mean(df_theta['s2'][-1000:]), color='red', linestyle='--', label='Média')
# Adjust the layout and add a main title
plt.tight_layout()Vemos que todos os parâmetros estão perto dos verdadeiros valores — como era de se esperar.
No próximo post, vou comentar sobre a convergência do MCMC. Fiquem ligados!
 . Então seria bom evitar. Na realidade, isso não é complicado: basta escolher uma distribuição que satisfaça
. Então seria bom evitar. Na realidade, isso não é complicado: basta escolher uma distribuição que satisfaça

 . Para aplicar o método de Gibbs, temos de saber amostrar de
. Para aplicar o método de Gibbs, temos de saber amostrar de
 .
. , vamos amostrar um novo valor para
, vamos amostrar um novo valor para  ,
,
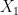 , condicional a
, condicional a 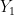 ,
,
 . Para obter as próximas, repetimos os passos,
. Para obter as próximas, repetimos os passos,

 , gere
, gere 
 é a média e
é a média e  é uma matrix de covariâncias. Vamos botar alguns números:
é uma matrix de covariâncias. Vamos botar alguns números:
 é normal com média
é normal com média  e variância
e variância  . Dá pra achar a média e variância de
. Dá pra achar a média e variância de  do mesmo jeito.
do mesmo jeito.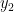 condicional a
condicional a 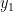 , e assim por diante. Mais fácil ver no código mesmo…
, e assim por diante. Mais fácil ver no código mesmo…


 é a taxa de desemprego numa data qualquer (
é a taxa de desemprego numa data qualquer ( ),
),  é um termo de erro (porque o modelo não prevê corretamente), e
é um termo de erro (porque o modelo não prevê corretamente), e  e
e  são parâmetros.
são parâmetros.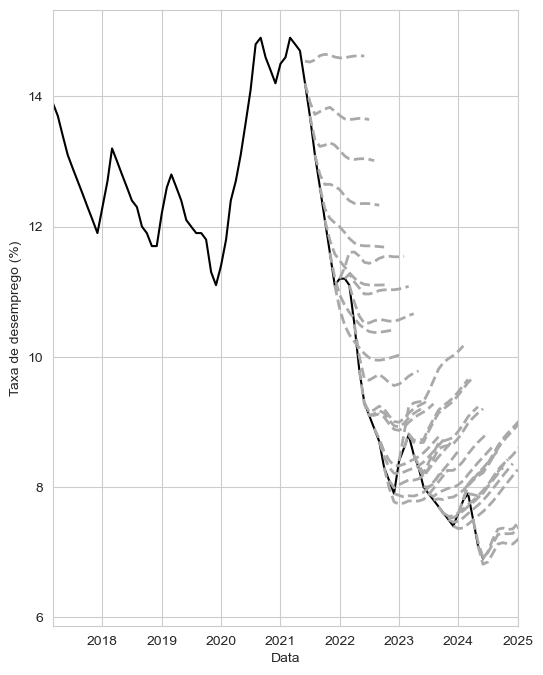
 e um conjunto de parâmetros
e um conjunto de parâmetros  ,
,  . Usando regras de probabilidade,
. Usando regras de probabilidade,
 , que vamos chamar de prior (a priori, pressuposta). A outra parte é a verossimilhança,
, que vamos chamar de prior (a priori, pressuposta). A outra parte é a verossimilhança,  , que descreve os observáveis dependendo dos parâmetros.
, que descreve os observáveis dependendo dos parâmetros. 

 significando “proporcional”, ou seja, faltando só multiplicar por uma constante.)
significando “proporcional”, ou seja, faltando só multiplicar por uma constante.) que satisfaz
que satisfaz  e
e  é o “kernel” de transição.
é o “kernel” de transição. .
. se ele for “próximo” de algo que veríamos da distribuição de interesse original
se ele for “próximo” de algo que veríamos da distribuição de interesse original  . De novo, vamos fazer isso porque é difícil amostrar de
. De novo, vamos fazer isso porque é difícil amostrar de  ), mas é fácil tirar uma amostra de
), mas é fácil tirar uma amostra de 
 ); caso contrário,
); caso contrário,  .
.
 para gerar um candidato Y
para gerar um candidato Y ) e repita o procedimento; caso contrário, aceite (
) e repita o procedimento; caso contrário, aceite ( )
) que definem localização, escala, e forma, respectivamente.
que definem localização, escala, e forma, respectivamente. . Se
. Se  . Se
. Se  .
.
![t(x) \equiv \begin{cases} [1+\sigma^{-1}\xi(x-\mu)] & \text{ se } \xi \neq 0 \\ exp(-\sigma^{-1}(x-\mu)) & \text{ caso contrário} \end{cases}](https://s0.wp.com/latex.php?latex=t%28x%29+%5Cequiv+%5Cbegin%7Bcases%7D+%5B1%2B%5Csigma%5E%7B-1%7D%5Cxi%28x-%5Cmu%29%5D+%26+%5Ctext%7B+se+%7D+%5Cxi+%5Cneq+0+%5C%5C+exp%28-%5Csigma%5E%7B-1%7D%28x-%5Cmu%29%29+%26+%5Ctext%7B+caso+contr%C3%A1rio%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=000&s=0&c=20201002)

 , o suporte é truncado em 0, vou escolher
, o suporte é truncado em 0, vou escolher  . Para terminar, o algoritmo implementado fica assim:
. Para terminar, o algoritmo implementado fica assim: