Esse post complementa o dashboard do nowcast eleitoral.
Seja por politicagem ou puro clubismo, há um grande interesse em saber quem está à frente em uma disputa eleitoral. A ferramenta mais utilizada são pesquisas eleitorais, o padrão-ouro em termos de validade. Diversas empresas entrevistam amostras representativas de eleitores e captam diretamente o interesse de voto. Porém, os resultados não apenas chegam esporadicamente mas também com informações defasadas (já que há um atraso entre a coleta de dados e a divulgação dos resultados). Esse atraso impossibilita uma análise de alta frequência (como testar os efeitos de uma fala no palanque, uma operação policial, uma denúncia).
No outro lado do espectro estão medições como o Google Trends. Ele entrega um sinal em tempo real sobre quanta atenção cada candidato está captando. O custo é óbvio: busca não é voto. Um pico de buscas por um dos candidatos pode refletir entusiasmo dos apoiadores, escândalo, ou simplesmente curiosidade. O nível absoluto é enviesado (presidentes em exercício são mais buscados por razões institucionais), e o sinal é ruidoso o suficiente para que ninguém leve a sério um modelo que prevê eleição olhando só para o volume de buscas.
A intuição deste projeto é que esses dois sinais são complementares, não substitutos. Pesquisas trazem informações sobre o nível com baixa frequência, enquanto o Google Trends traz variação com alta frequência.
Um filtro de Kalman é a ferramenta natural para fundir os dois: extrai a trajetória latente da intenção de voto, ponderando cada observação pela sua volatilidade.
O resultado é um nowcast diário das intenções de voto, com banda de incerteza, que se atualiza assim que sai uma pesquisa nova ou que o Trends acumula evidência suficiente para mover a estimativa.
Método
Estados e observações
Modelamos três quotas de votos válidos — Lula, Bolsonaro e Outros — como um vetor latente 

Trabalhar em 

A cada dia 
– 
– 
A escolha de usar a variação (e não o nível) do Google Trends é deliberada: como discutido na introdução, o nível absoluto de buscas é enviesado e tem componentes que nada têm a ver com intenção de voto. Já a variação suaviza esse viés de nível e mede a direção do interesse — exatamente a informação de alta frequência que queremos extrair.
Equações do modelo
Equação de transição

com 
Equação de medida

onde:
– 
– 
– 
Como 

e aplicamos as equações usuais do Kalman com 
Tratamento de dados faltantes
Em mais da metade dos dias da amostra, falta pelo menos uma das fontes (e em muitos dias, todas as pesquisas). O EKF lida com isso naturalmente: para cada dia, identificamos o subconjunto de observações disponíveis e aplicamos as equações de atualização restritas a esse subconjunto. Dias completamente vazios passam pela predição sem atualização — o estado avança, mas a variância também cresce, o que é exatamente o comportamento desejado: na ausência de informação, a incerteza aumenta.
Uma sutileza importante: pesquisas não chegam pontualmente no dia da divulgação. Cada pesquisa cobre, em média, os cinco dias anteriores. Atribuímos a observação de cada pesquisa a esses dias passados (não ao dia da divulgação) e ponderamos pelo 
Estimação
Os 20 parâmetros do modelo (interceptos, loadings, variâncias de estado, variâncias de medida) são estimados por máxima verossimilhança via SLSQP, com bounds para garantir identificação. As variâncias de estado, em particular, são limitadas a um intervalo apertado em log — isso evita que o filtro “explique” toda a variação dos dados como ruído de medida (estimativa achatada) ou como ruído de processo (estimativa que copia as pesquisas).
A inicialização do estado usa quotas neutras (40/40/20), e a covariância inicial é difusa — após algumas dezenas de observações, a influência do prior é desprezível.
Resultados
A última estimativa do modelo (suavizada, vintage 27/04/2026) traz:
| Candidato | Estimativa (%) | IC 95% |
| F. Bolsonaro | 47,2 | 46,0 — 48,4 |
| Lula | 40,8 | 39,6 — 42,0 |
| Outros | 12,0 | 10,8 — 13,2 |
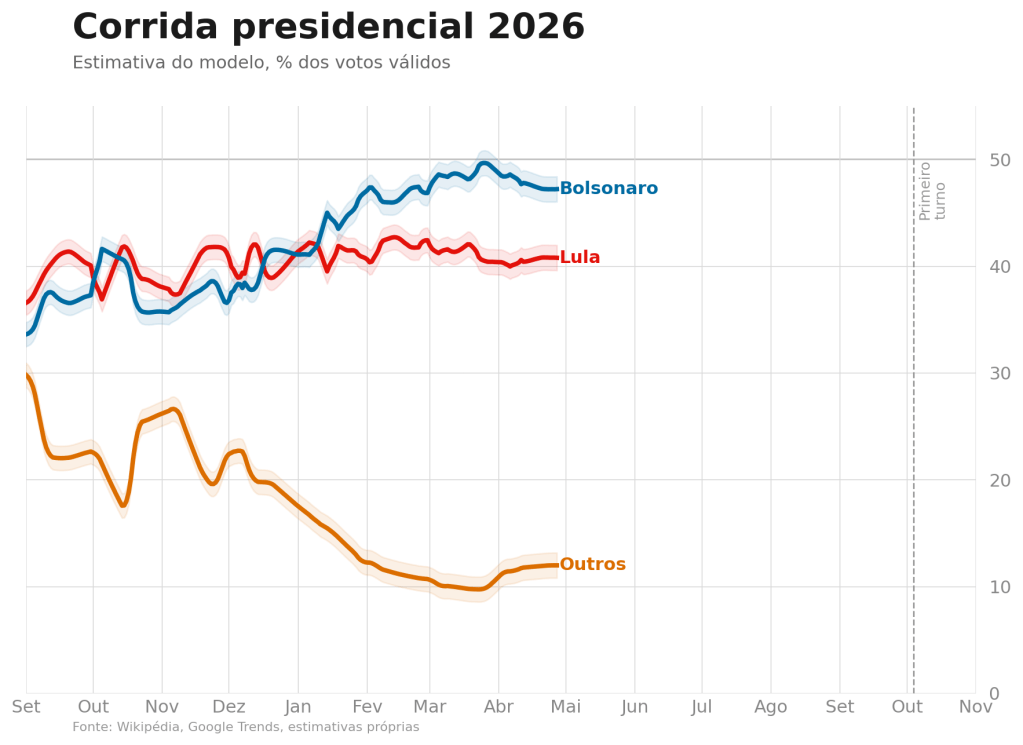
O modelo não é uma bola de cristal. A eleição está a meses de distância, eventos podem virar a mesa, e nenhuma fusão de fontes contemporâneas resolve esses riscos. Mas como leitura condicional ao que sabemos hoje, o nowcast entrega o que se propõe: uma estimativa diária, calibrada e auditável da disputa.

Deixe um comentário